
Tuesday 8:24 am
14th May 2019 ·
Reading Open Graph Meta Properties
Last night we pushed a small update to improve link sharing on Mirror Island.
When people share links, finding the right information can be made easy if Open Graph tags are available. Some guesswork can be made by using HTML's <title> tag for the link text, and allowing people to choose one of many images found on the page (if we're lucky).
Previously, links added to a blank document used to look like this:
Thankfully the Open Graph protocol (http://ogp.me/) provides a number of useful <meta> tags allowing easy and a more accurate way of sharing links between websites and networks. In the <head> section of an HTML page we might find these meta tags:
<meta property="og:title" content="World largest steam locomotive is back! Big Boy 4014 hits the main line">
<meta property="og:url" content="https://www.youtube.com/watch?v=RR7Q27cIEvo">
<meta property="og:image" content="https://i.ytimg.com/vi/RR7Q27cIEvo/maxresdefault.jpg">
<meta property="og:description" content="They said it couldn't be done. It was too heavy, too long, it burned too much fuel, and would cost too much to restore. But they were wrong. Union Pacific, B...">Using these Open Graph tags, links generated in new posts now look like this:
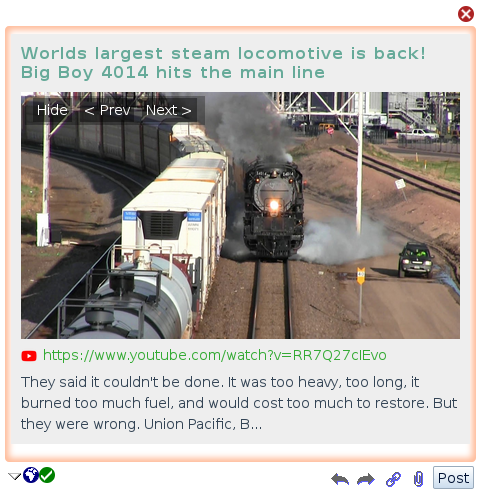 Much better.
Much better.
At this point each Open Graph meta tag is self-explanatory. So now we know what tags to read, the next part is how to read them. Usually, some usable information can be extracted by using regexp to read tags. However, regexp isn't the best solution when dealing with markup tags.
The method we use is to read the DOM (Document Object Model) with PHP's DOMDocument class. It can also handle most errors that would occur if using regexp, such as tags inside comments or javascript code. First, we load the web page as an HTML string. Next, the string is loaded in to a blank domDocument. From here we can navigate and read data from the DOM tree.
The following lines of code can read the Open Graph url, title, image, and description. This is a cut-down version of what we used, in order to focus on DOM features in this article. This code snippet is free to use for whatever purpose you see fit.
/* Sanitise the input */
$url = substr(trim(stripslashes($_POST['url'])), 0, 1024);
/* Load the HTML as a DOM document
*/
$html = file_get_contents($url);
$dom = new domDocument;
$dom->preserveWhiteSpace = false;
$dom->loadHTML($html);
/* Fetch data from any Open Graph tags
*/
$og_url = '';
$og_title = '';
$og_image = '';
$og_description = '';
$metatags = $dom->getElementsByTagName('meta');
foreach ($metatags as $meta) {
$metaproperty = $meta->getAttribute('property');
$metacontent = $meta->getAttribute('content');
if ($metaproperty == "og:url") {
$og_url = $metacontent;
} else if ($metaproperty == "og:title") {
$og_title = $metacontent;
} else if ($metaproperty == "og:image") {
$og_image = $metacontent;
} else if ($metaproperty == "og:description") {
$og_description = $metacontent;
}
}
/* Use the Open Graph title if available, otherwise
fall back to the HTML document's title tag */
$title = '';
if ($og_title) {
$title = $og_title;
} else {
$headtitle = $dom->getElementsByTagName('title');
foreach ($headtitle as $t) {
if ($t->nodeValue != '')
$title = $t->nodeValue;
}
}
/* Overwrite the provided URL with the Open Graph
provide one if available. */
if ($og_url) {
$url = $og_url;
}
/* From here on, $og_image and $og_description are used
as-is */